Applying Deep Learning to detect Rhegmatogenous Retinal Detachment
Retinal detachment is an eye disease and is one of the most serious ocular emergencies. It occurs after a layer of the retina - essential tissue for vision - is lifted from the pigmented epithelial tissue, dragging the blood vessels that supply nutrients and the eye with it. If the retina is no longer nourished through contact with the pigment epithelium layer, cell death and a progressive and functional loss of vision or of the detached portion of the retina occur after 48 hours.
However, the retina can be re-attached surgically, resulting in ocular improvement, as long as the detachment time is not excessive (Heussen N. et al., 2012). Below it is demonstrated how machine learning and deep learning techniques can play a crucial role in quickly saving the eyes of a patient with Rhegmatogenous Retinal Detachment.
Retinal detachment: types and consequences
There are four types of retinal detachment:
- Rhegmatogenous Retinal Detachment (RRD): the most frequent, is due to a break in the retina that allows the vitreous, gelatinous liquid that is inside the eye, to enter the subretinal space, thus allowing the detachment of its adherent portion;
- Tractional: typical in cases of retinal ischemia, it is generated by fibro-vascular tissue bridles that exert a centrifugal traction on the retina capable of ungluing it;
- Exudative: it is due to the presence of fluid under the retina following inflammation or vascular lesions;
- Mixed forms.
Rhegmatogenous Retinal Detachment is a serious condition that can lead to blindness, nevertheless the possibility of cure is directly proportional to the timeliness of appropriate treatment that anticipates the period of cell death of the retina. Early diagnosis and rapid intervention play a fundamental role, and in this case Deep Learning techniques represent an aid capable of meeting these needs. In the study by Ohsugi and collaborators, Machine Learning technologies are applied to detect RRD, using ultra-wide field fundus images and studying their performance (Ohsugi, H., Tabuchi, H., Enno, H. et al., 2017).
These images can be realized thanks to techniques conducted by means of scanning laser ophthalmoscope (SLO), an instrument used for the evaluation of the fundus of the retina. It was designed to capture images of the retinal layers simultaneously with confocal images of the fundus (W H Woon, F W Fitzke, A C Bird, J Marshall, 1992). Wide field fundus images can be acquired easily without pupillary mydriasis and without causing medical complications, so even examiners not qualified to perform ophthalmological surgeries can acquire the images in a completely safe way, making this instrument ideal especially in cases of emergency in which ophthalmologists are not available.
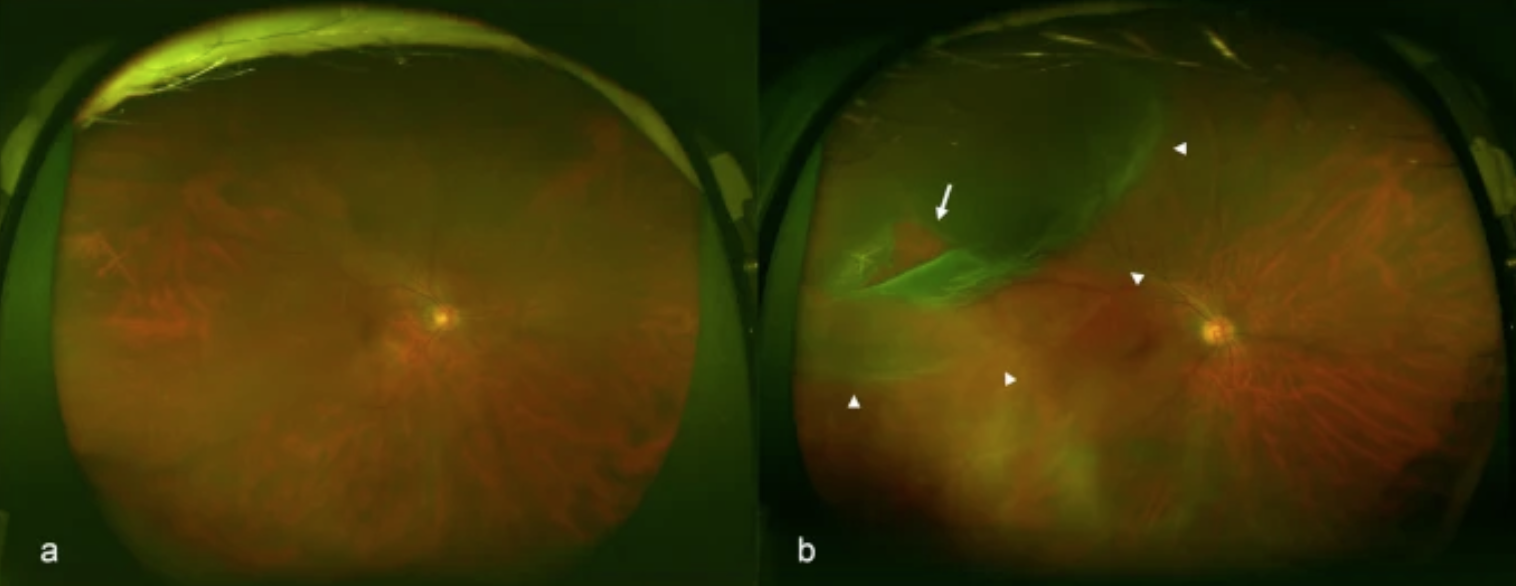 Representative fundus images obtained by ultra wide field scanning laser ophthalmoscopy. Ultra wide field right fundus images without rhegmatogenous retinal detachment (RRD) (a) and with RRD (b). The arrow indicates the retinal break and the arrowheads indicate the areas of RRD.
Representative fundus images obtained by ultra wide field scanning laser ophthalmoscopy. Ultra wide field right fundus images without rhegmatogenous retinal detachment (RRD) (a) and with RRD (b). The arrow indicates the retinal break and the arrowheads indicate the areas of RRD.
Machine Learning and RRD early diagnosis
The study evaluates precisely the ability of a deep learning technology to detect RRD using images obtained through SLO.
A Machine Learning model uses a multilayer CNN capable of automatically learning the characterizing patterns of the images and making them a classification system (Deng, J. et al., 2009).
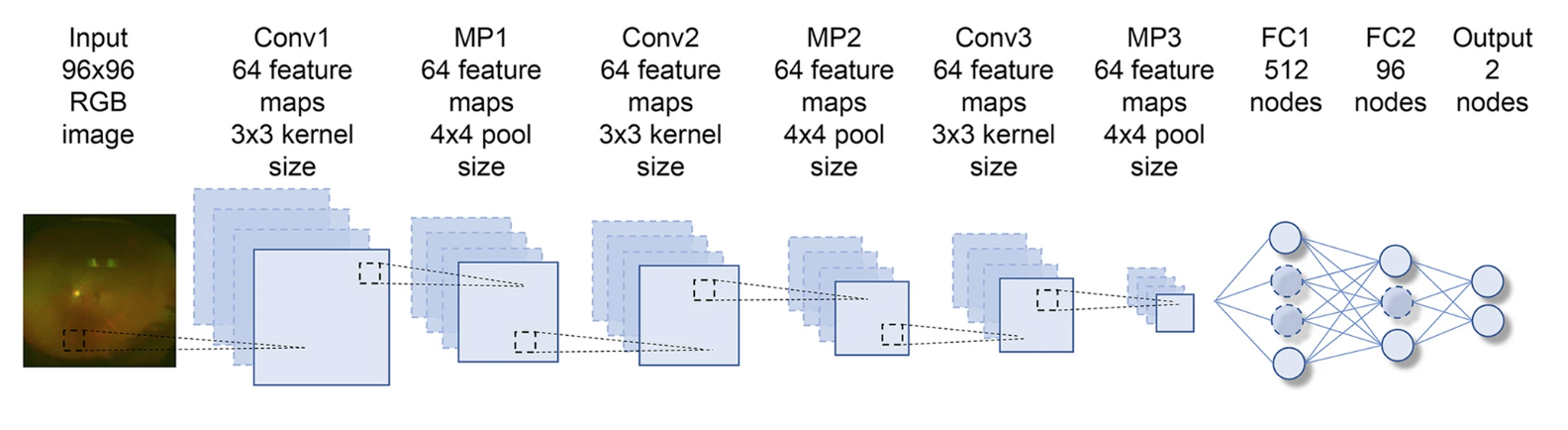 CNN architecture used. The Input is represented by the RGB 96x96 pixel image. Each of the convolutional layers (Conv1–3) is followed by an activation function layer (ReLU), pooling layers (MP1–3), and two fully connected layers (FC1, FC2).
CNN architecture used. The Input is represented by the RGB 96x96 pixel image. Each of the convolutional layers (Conv1–3) is followed by an activation function layer (ReLU), pooling layers (MP1–3), and two fully connected layers (FC1, FC2).
The convolutional level obtains the characteristics of the input through convolutional filters, the maximum levels of pooling (MP1, MP2 and MP3) allow a more generic recognition. The last two layers (FC1, FC2) are completely connected and remove spatial information from the quantities of extracted features and statistically recognize the objective that CNN aims to achieve. For the training of the neural network, 100 images were processed, in addition an optimization algorithm called AdaGrad was implemented to correctly train the network weights.
411 images from 407 RRD patients and 420 images from 238 non-RRD patients were used. The deep learning model demonstrated a high sensitivity of 97.6% [95% confidence interval (CI), 94.2-100%] and a high specificity of 96.5%. The model used, therefore, can improve medical care and increase the timeliness of intervention, resulting in an early diagnosis that can prevent RRD-derived blindness.
Hope you found it interesting. Thanks for reading.
Bibliography
- Heussen N. et al. (2012). Scleral buckling versus primary vitrectomy in rhegmatogenous retinal detachment study (SPR study): Risk assessment of anatomical outcome. SPR study report no. 7. Acta Ophthalmologica.
- Ohsugi, H., Tabuchi, H., Enno, H. et al. (2017). Accuracy of deep learning, a machine-learning technology, using ultra–wide-field fundus ophthalmoscopy for detecting rhegmatogenous retinal detachment. Scientific Reports, Article number: 9425.
- W H Woon, F W Fitzke, A C Bird, J Marshall. (1992). Confocal imaging of the fundus using a scanning laser ophthalmoscope. British Journal of Ophthalmology.
- Deng, J. et al. (2009). Imagenet: a large-scale hierarchical image database. Computer Vision and Pattern Recognition. IEEE Conference on Computer Vision and Pattern Recognition, 248–255.